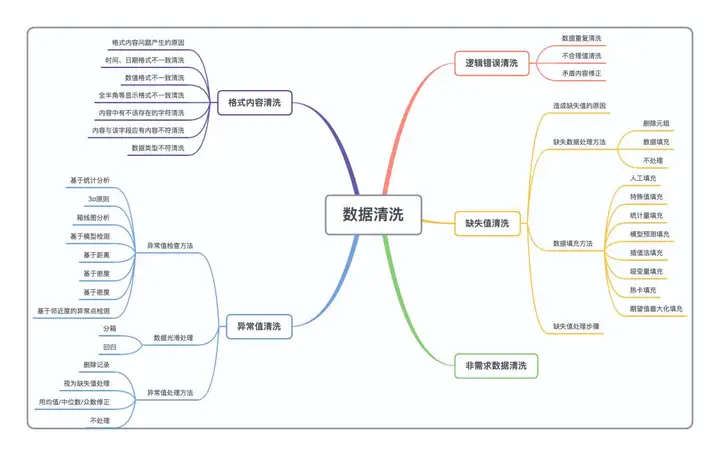
数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。
我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
“脏”数据的类型
1 残缺数据
这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
2 错误数据
这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
3 重复数据
对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。
对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。
数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
数据清洗有四个关键点
1 完整性
单条数据是否存在空值,统计的字段是否完善
2 全面性
观赏某一列的全部数值,我们可以通过比较最大值,最小值,平均值,数据定义等来判断数据是否全面
3 合法性
数值的类型、内容、大小是否符合我们设定时候的预想。例如:人类年龄超过1000岁,这个数据就是不合法的。
4 唯一性
数据是否重复记录,例如:一个人的数据被重复记录多次。
我们清理数据的标准是使得数据标准,干净,连续。